From Geeks to Programmers, whenever we encounter the word 'Database', we think about the applications like SQL Server, MySql, or Oracle. And, whenever someone names these applications, we think about insert-delete-updates with a loads of Sql queries. So, basically we are familiar with the world of Relational Database Management Systems (RDBMS). Database is equivalent to RDBMS to us.
NoSql - An old but effective concept in the world of Database
There is an another concept is present in the market and from the last few years, that concept has grown up enough to be used by many of the tech-giants. The concept is known as NoSql (Not-only Sql). In RDBMS, we store data in a tabular format. We have tables, fields, keys and relationships between all of them (that's why it is named 'Relational'). Everything in RDBMS is schema-based. But in case of NoSql databases, there are no tables and no schemas. It is designed for distributed data stores where very large scale of data storing needs (for example Google or Facebook which collects terabits of data every day for their users).
NoSql database types
- Document Oriented - Data are stored in Documents. Each document may have several key-value pairs with a complex data structure (CouchBase, MongoDb etc.)
- Graph Oriented - These are used to store information about networks, such as social connections. (Allegro, OrientDb etc.)
- Key-value Oriented - Every single item in the database is stored as an attribute name (or "key"), together with its value (MemcacheDb, Redis, Riak etc.)
- Wide-column Oriented - They store columns of data together, instead of rows. (Cassandra, HBase etc.)
Distributed Database and NoSql
A distributed database is a database in which portions of the database are stored on multiple computers within a network. The DDBMS synchronizes all the data periodically and, in cases where multiple users must access the same data, ensures that updates and deletes performed on the data at one location will be automatically reflected in the data stored elsewhere.
Distributed Systems are vastly used today where we need to store very large amount of data. In a distributed system, the servers may be kept in different rooms, in different buildings, even in geographically disbursed locations.
Most of the NoSql systems support Distributed Architecture. We can built-up a distributed DBMS easily with NoSql solutions. Later, I will explain what exactly are the needs of a distributed system.
Relational and NoSql data models are, obviously, totally different. The relational model takes data and separates it into many interrelated tables that contain rows and columns. Tables reference each other through foreign keys (the most confusing thing in RDBMS). When looking up data, the desired information needs to be collected from many tables (often hundreds in today’s enterprise applications) and combined together before received by the application . Similarly, when writing data, the write needs to be coordinated and performed on many tables in the same way.
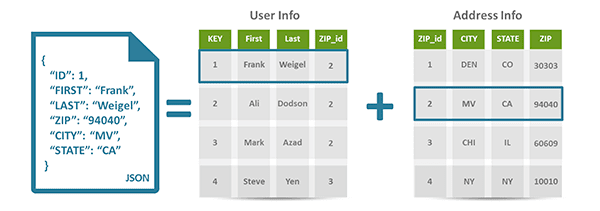
NoSql databases are very different from RDBMS. For example, a document-oriented NoSql database takes the data to be stored and aggregates it into documents using the JSON (Javascript Object Notation. Visit this link for details) format. A JSON document, for example, can take all the data stored in a row that spans 20 tables of a relational database and aggregate it into a single document. Aggregating this information may lead to duplication of information, but since storage is no longer cost due to the distributed architecture, the resulting data model becomes more flexible and rapidly improves read and write performance which is very effective for web-based applications.

{kind=link}
Another major difference is that RDBMS have rigid schemas while NoSql models are schemaless. Relational technology requires strict definition of a schema to store any data into a database. Changing the schema once data is inserted is a big deal (we think 100 times before doing that) – the exact opposite of the behavior desired in the Big Data era, where we, the developers need to constantly and rapidly incorporate new types of data to enrich our apps.
Scalability - here RDBMS fails!
To deal with the increase in concurrent users (once again, like Google or Facebook) and the amount of data, applications and their underlying databases need to scale using one of two choices: scale up or scale out. Scaling up is a centralized approach that relies on bigger and bigger servers, i.e. adding more RAM , HardDisks and/or processor cores to a single server. Scaling out is a an approach that splits the load on a bunch of physical or virtual servers. This scale out approach is based on the Distributed architecture, which I have explained earlier. Scale out is much more cheaper and reliable than the Scale Up approach. So, whenever we think about scalability, we think about the Distributed Architecture.
When No. of Users increase, we go with a Scale Out approach with our Web/Application Servers. We add more web servers, and the performance of the application remains same, sometimes gets better.
RDBMS mostly deal with Scale Up approach, which is costly and the performance decreases when there will be more data store (about some terabits). But, in case of NoSql, we use the same concept as Web Server. We use Scale Out approach to add more small db servers concurrently. This approach obviously increases the cost, but the performance also gets better when we add more servers.

{kind=link}
MongoDb - a popular NoSql solution
MongoDb is nothing but a NoSql database. So, all the characteristics of NoSql databases, which I have discussed above, can be found in MongoDb. So, what exactly MongoDb is?
MongoDb is a Document oriented NoSql Database. It uses BSON (a more extended form of JSON, but looks exactly like JSON) to store the documents and it is fully written in C++.
These are several useful MongoDb features which give us literally a wing to fly -
- Indexing - Any field in a MongoDB document can be indexed, exactly like indices in RDBMS. We can add secondary and compound indexes also.
- Replication - A replica set consists of two or more copies of the data. Each replica may act as the primary or secondary replica at any time, depending on the availability The primary replica is responsible to handle the write and read tasks and, the Secondary replica(s) maintain a copy of the data on the primary replica.

Replication in MongoDb - Sharding - MongoDB scales horizontally using sharding. In sharding there are basically three types of MongoDb components are used, one is MongoDb shards, second one is query routers and last one is the Config Servers. The Shards are basic MongoDb instances (called 'mongod') which are used to store data. A shard may contain one or more replica sets.
- File Storage - MongoDb includes a function named 'GridFS', which allows users to use MongoDb as a file system. With the help of Load balancing and Data replication features, MongoDb does this job very efficiently. In Distributed MogoDb systems, files are distributed and copied multiple times between machines, which leads to a fault-tolerant File System.
- Javascript Queries - Query is an essential part of any Database. MongoDb supports javascript to write queries directly into the Database. Javascript acts as the 'SQL' in MongoDb. Any operations including Insert-Update-Delete can be done using Javascript queries.
- Aggegation - MongoDb doesn't support Aggregate functions (like Group By) in queries. Instead of that, we can use Map-Reduce technique (visit this page for details) to do the aggregation in MongoDb.
- Multi-language Support - MongoDb supports different programming and scripting languages for application development. It supports Python, PHP, Java, C# and all other major programming languages. It also provides DRM (Document Relational Mapping, exactly like ORM or Object Relational Mapping for RDBMSes) to write codes efficiently.
The Query Routers run 'mongos' instances, which directly interface with the application layer (the database calls made from an application) and redirects the operation to an appropriate shard or a group of shards. A sharded cluster can contain more than one query router to divide the client request load.
Config servers store the cluster’s metadata which is basically a mapping of the cluster’s data set to the shards. The query router uses this metadata to target operations to specific shards.
We can build a very efficient fault-tolerant and load-balanced system by applying Sharding and Replication together.
We can build a very efficient fault-tolerant and load-balanced system by applying Sharding and Replication together.
 |
| Sharding with MongoDb |
Documents - the heart of MongoDb
We already know that MongoDb stores Documents instead of rows. So, how does it looks like??
{
_id: '5099803df3f4948bd2f98391',
name : 'shubhadeep banerjee',
city : 'kolkata',
age : 25,
company : 'Algonics'
}
The above is a sample document in MongoDb. Here, the _id field is auto-generated. It contains the information like Document Serial No, Datetime of creation etc. in an encrypted format. A single document can be upto 16MB long.
A collection of documents is called a Collection (equivalent to Tables in RDBMS). We create a collection without any particular definition, and Create, Manipulate and Retrieve documents from that collection.
{
_id: '5099803df3f4948bd2f98391',
name : 'shubhadeep banerjee',
city : 'kolkata',
age : 25,
company : 'Algonics'
}
The above is a sample document in MongoDb. Here, the _id field is auto-generated. It contains the information like Document Serial No, Datetime of creation etc. in an encrypted format. A single document can be upto 16MB long.
A collection of documents is called a Collection (equivalent to Tables in RDBMS). We create a collection without any particular definition, and Create, Manipulate and Retrieve documents from that collection.
What Algonics do with MongoDb?
In some of our recent projects, we have used MongoDb to implement distributed and efficient Big Data solutions. In one of those projects, we had a situation, where a large number of electrical devices (almost 13,000 industrial energy meters) would send data to a server in a particular interval, resulting almost 60-70 million db-access per day . The no. of devices would increase time to time. We have used MongoDb and Python combo on Linux Ubuntu servers (MongoDb runs best on Linux) to handle this situation. MongoDb servers can easily extended be using the Sharding technique, and we can add more server in future as the load increases. Hence, we can build a Load-balanced, Distributed, Fault-tolerant, fast and reliable Distributed Database using MongoDb, without much more technical complexities.
The Bottom Line - should you use it?
Now you have completed the whole blog, and should be thinking to wave your hands to RDBMS, and use MongoDb or other NoSql databases in your future projects. But keep one thing in your mind that, NoSql is not for the beginners, never was, and never will be. If you are an amateur, and have just started programming, please learn RDBMS properly. NoSql databases are completely schema-less, so you need to implement the schema through your code. It would really be a tough job for any beginner.
But, if you are confident, you know what to do, and can't control your excitement to use this excellent technology, do it now. Download MongoDb, choose your favorite language and start programming. I bet, it won't disappoint you.
Don't forget to comment and share. For any confusion, place your question below, we are here to help you.
Bye for now. Meet you on my next blog. Till then, Happy Programming!
Visit our website | Visit Our LinkedIn Page | Search us on Google
But, if you are confident, you know what to do, and can't control your excitement to use this excellent technology, do it now. Download MongoDb, choose your favorite language and start programming. I bet, it won't disappoint you.
Don't forget to comment and share. For any confusion, place your question below, we are here to help you.
Bye for now. Meet you on my next blog. Till then, Happy Programming!
Visit our website | Visit Our LinkedIn Page | Search us on Google
Excellent article, can you give the link for MongoDB download?
ReplyDeletehttp://www.mongodb.org/downloads
ReplyDeleteDownload the stable 2.4.10 version for 64 bit systems. In 32 bit systems max database size for each database is 2gb.
Liked this article too.
ReplyDelete:)
Thanks Sonali :)
DeleteExcellent Article , Really can't control the excitement .
ReplyDelete